Playing with Parsers
I wrote the same program in 10 different programming languages. Here’s how the performance of the different implementations stack up to each other.
Introduction
I like programming languages. Their syntaxes, their semantics, the communities behind them - all these factors entice me to spend time learning different tools of the software engineering trade. One approach I often take for learning new languages is to reimplement a program I’ve written in another language. I like doing this because so long as the language paradigms are similar, I can use my prior implementation as a guide to writing the new one. Moreover, once I feel more comfortable in the new language, I can refine its implementation to be more idiomatic.
A program that I like to reimplement the most often is a simple arithmetic expression parser. About a week ago, I reimplemented this parser in Rust for practice, and suddenly wondered how the performance of this implementation would compare to ones in other languages. I expected it would of course be faster than a Python implementation, but what about one in Go, or even Haskell? I’m aware that studies such as the Benchmark Games already exist, but I thought conducting my own study could be fun. So I decided to go all in - I would implement the same program in all the languages I could, and then have them all race to the finish!
Background
I implemented my parsers in C, C#, C++, Go, Haskell, Java, Javascript, Python, Rust, and Typescript. Here are the steps I took to do that, sans downloading all the necessary compilers/interpreters.
The Arithmetic Expression Grammar
First, I designed a small language of arithmetic expressions. Here is the full grammar in EBNF form:
expr = addsub;
addsub = muldiv {('+' | '-') muldiv};
muldiv = neg {('*' | '/') neg};
neg = {'-'} parenint;
parenint = ('(' expr ')') | int;
int = digit{digit};
digit = 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9;
Operator Precedence
Next I decided on the the operator precedence levels. Here they are, from greatest precedence to least:
- parenthesized expressions, integer literals
- unary negation
- multiplication, division
- addition, subtraction
The Lexer and Parser
Then, I wrote the lexers and parsers. In all languages (except for Haskell, which I explain in the next subsection), I implemented the lexer as a function which takes a string as input and returns a vector/list/arraylist of tokens as output. The parser is just an LL(1) recursive descent parser, and I implemented it as a class/struct with methods for recursively parsing a given sequence of tokens to an integer result1. For more information, check out Compilers: Principles, Techniques, and Tools. I wrote the first parser in Python, and based it off the one in chapter 2.19 of The Python Cookbook, 3rd edition. I made it a point to only use libraries/packages/modules that each language ships with, so that the only difference in the parsers would be the implementation language. For all the gory details, you can refer to this GitHub repo containing all code for this study.
A Note on the Haskell Implementation
For most of the implementations, I wrote the same program: a lexer and a LL(1) recursive descent parser. I implemented the Haskell parser a little differently however, using parser combinators. I did this for three reasons: 1) I wanted to practice writing parser combinators. 2) It felt like the more natural way to parse text in Haskell. 3) I wanted to see how my naive implementation using parser combinators stacked up to my naive implementation of a recursive decent parser in the other languages.
Testing
After writing my parsers, I needed a way to test that they were correct. One way to to do this would be to implement a set of test cases in each parser’s language. That would be pretty tedious, however, so I decided to fuzz test them instead.
To fuzz the parsers, I ran them all on a set of randomly generated test inputs, and compared their results to that of bc. These inputs consisted of a hundred, a thousand, ten thousand, a hundred thousand, and a million expressions. I considered a parser as passing a test if its output for that test matched that of bc2. All my parsers passed all my tests before I ran conducted my experiment.
I wrote a Python script to generate these test inputs.
Basically, it recursively generates binary and unary expressions in the grammar until it reaches a specified maximum nesting depth, and then just emits an integer.
To maintain operator precedence, it parenthesizes all subexpressions.
I used methods described in this paper to ensure that I did not emit expressions which could introduce undefined behavior, such as divide-by-zero and integer overflow errors.
This little script was fun to write, so if you’d like to take a look at it please check out the file gen_exprs.py in the repo (the code is commented!).
Experimental Setup
I used the test inputs I described in the last section to evaluate my parsers. I ran each parser on each input twice to warm up the cache, ran the parser five more times on the input, and then took the average of the five execution times as the result for that parser on that input.
Hardware
I developed my parsers and evaluated them on a Dell XPS 13 9310 (0991) Notebook with 16 GB of RAM and an 11th Gen Intel i7-1185G7 CPU clocked @ 3.00GHz. I ran on all my tests and conducted my evaluation on a single core.
Software
- Kernel: 5.14.0-1045-oem
- Operating System: Ubuntu 20.04.4 LTS x86_64
Language Technology
| Language | Compiler/Transpiler | Interpreter |
|---|---|---|
| C | gcc (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0 | N/A |
| C# | Microsoft (R) Visual C# Compiler version 3.9.0-6.21124.20 (db94f4cc) | Mono JIT compiler version 6.12.0.182 (tarball Tue Jun 14 22:29:01 UTC 2022) |
| C++ | g++ (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0 | N/A |
| Go | o1.18.4 linux/amd64 | N/A |
| Haskell | The Glorious Glasgow Haskell Compilation System, version 8.10.7 | N/A |
| Java | javac 11.0.15 | openjdk 11.0.15 2022-04-19 |
| Javascript | N/A | Node v10.19.0 |
| Python | N/A | Python 3.8.10 |
| Rust | rustc 1.61.0 (fe5b13d68 2022-05-18) | N/A |
| Typescript | tsc 4.7.4 | Node v10.19.0 |
Results and Observations
I’ve recorded all the raw results of my experiments in the file results.csv in this study’s GitHub repo.
You can go here to view it on Github, which lets you easily filter and search through it.
The time it took the parsers to run on 100, 1K, and 10K lines of input were comparable, so I graphed them in a bar chart:
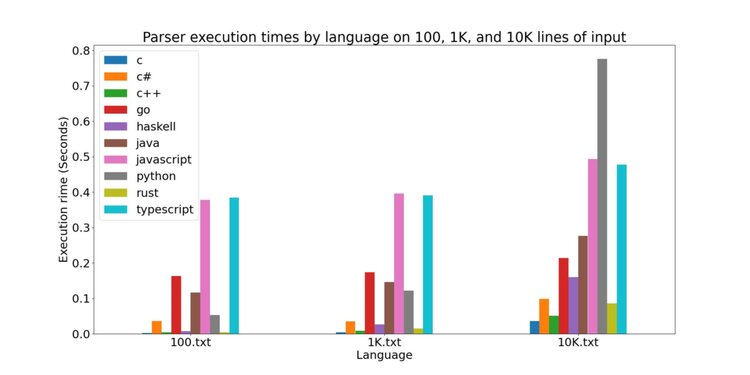
The C/C++/Rust implementations were the fastest. This is likely because these languages aren’t garbage collected, and have minimal runtime environments (basically just their standard libraries). The C# implementation was also pretty fast on the 100 and 1K lines of input, but in the rightmost group you can see it start to slow down. I’m not sure why C# is so fast on the smaller inputs; if anyone knows why and would be willing to share I’d appreciate it :)
Next up, we have the Haskell, Java, and Go implementations. These languages are garbage-collected and have larger runtimes, so it makes sense that they would be a bit slower.
Finally, there are the Javascript, Python, and Typescript implementations. I find the results for these implementations most intriguing. Naturally, they are slower than the other implementations since they are interpreted and not compiled, but I’m amazed at how poorly the Python implementation scales. It outperforms the Javascript and Typescript implementations on the smaller inputs, but its performance starts to fall off at 10K lines of input. Meanwhile, the Javascript and Typescript implementations scale much better. I think it is interesting to note that the Typescript implementation is just slightly faster than the Javascript one - the Typescript transpiler must write better Javascript than I do!
Now, let’s move on to the 100K lines of input. I could still fit all the parser execution times for this file in a single bar chart, so here it is:
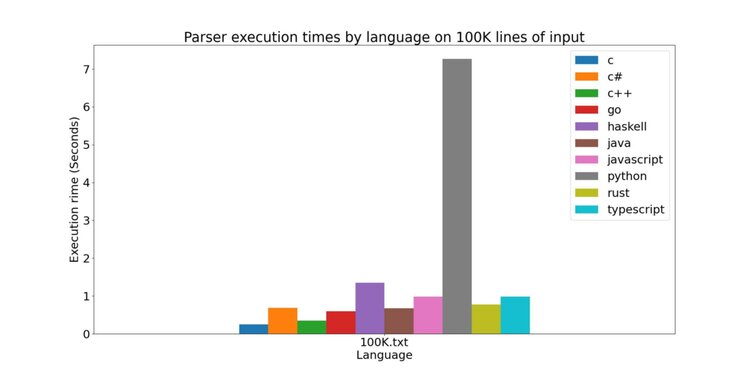
The Python implementation continues to scale poorly. I tried to improve its performance a few times by changing how the parser’s lookahead worked, but in the end I wasn’t able to salvage it. Maybe if I tried a bit harder I could have found a way to get closer to the Javascript and Typescript implementations, but oh well.
Meanwhile, the Haskell implementation begins to really slow down as well.
I’m not entirely sure why this is.
It may because it operates on Strings instead of ByteStrings.
Or could be because the implementation is rather naive, and doesn’t make efficient use of memory.
In any case, the next time I decide to solve a parsing problem using functional programming, I’ll make use of an industrial-strength parser combinator library such as Megaparsec or Attoparsec instead of hand-rolling my own.
Finally, I graphed the parser execution times on the 1M lines of input. I did not plot the execution times for Python and Haskell in this graph since they took so much longer than the other parsers to finish (13.4s and 72.5 sec, respectively).
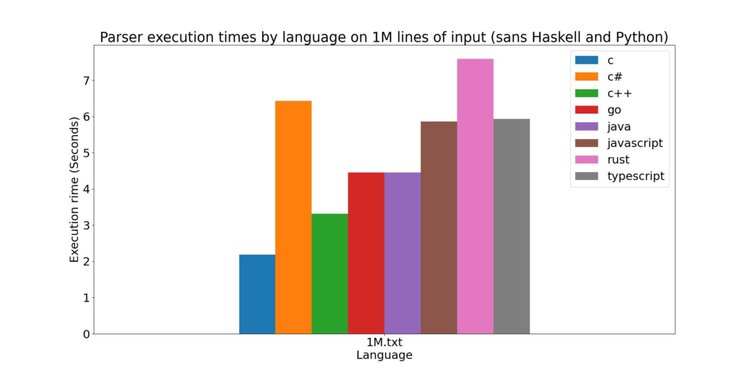
What I found most shocking here is how slow the Rust implementation is at this point. Since Rust isn’t garbage collected, I would expected it to keep pace with C and C++. Instead, it lags behind even the interpreted languages. I though that surely I must be doing something wrong, so I did some digging and stumbled across this article by Renato Athaydes. Apparently, Rust is full of little idioms that one must use if they wish to write optimal Rust code. This disappoints me, because while these “rustisms” look elegant after you have seen them, they are unobvious. Please check out the linked blog posts for examples. Don’t get me wrong, I think it’s normal for a programmer to have to know certain language idioms in order to squeeze every last drop of performance out of their code. What I don’t like about Rust, however, is that its idioms are not akin to ones you would use in other imperative languages (e.g., favoring static variables over pointers/references to improve data locality and reduce cache accesses). So if you invest time in learning them, you may be able to write better Rust code, not more efficient code in another language. More likely than not, these idioms will not translate well (if at all) to other languages.
Side Notes
- The code size of the C implementation is the greatest of all the parsers I wrote, and of course I ran into memory errors while implementing it :)
- Go forced me to write more verbose code and to pass error messages up the call stack, but it made it easier to do so. I still ran into memory errors though.
- The Haskell implementation is by far the shortest, but some could see this as a downside since at times the code can be a bit terse. Or just illegible if you’re not familiar with parser combinators 🤷♂️️.
- With the Javascript implementation I had fun trying to convert
-0to0:-) - Python was the easiest to implement, and I tried to refactor it a few times to make it faster. In the end I gave up - Python is just so slow.
- Rust’s enum variants gave me an intuitive way to define tokens, and partly thanks to the language itself I did not encounter any memory errors.
Bottom Line
- If I want to write a quick script to process large text files, I may reach for TypeScript in the future instead of Python, since it provides the benefits of static typing and better performance.
- Naively implemented imperative parsers are likely to be faster than naively implemented functional parsers.
- Rust has a bit too many esoteric idioms for my liking.
Future Work
These parsers aren’t perfect. Honestly, they’re not even idiomatic in the languages they are implemented in. It would be interesting to see another study comparing the performance of idiomatic parser implementations (or maybe popular parsing frameworks?) across languages. I might do this in the future, but if anyone else wants beat me to it I’d be cool with that.
1 Technically, I think it would be more accurate to call these parsers interpreters since they don't construct abstract syntax trees out of their inputs, but I prefer to use the word parser because it's quicker to write and say.
2 This means I am treating bc as the ground truth for my testing.